

一个热门社交网络爬虫工具,支持多个常用社交软件内容的爬取。
一、介绍
目前能抓取小红书、抖音、快手、B站、微博的视频、图片、评论、点赞、转发等信息。
原理:利用playwright搭桥,保留登录成功后的上下文浏览器环境,通过执行JS表达式获取一些加密参数 通过使用此方式,免去了复现核心加密JS代码,逆向难度大大降低。
二、使用说明
创建并激活 python 虚拟环境:
# 进入项目根目录
cd MediaCrawler
# 创建虚拟环境
python -m venv venv
# macos & linux 激活虚拟环境
source venv/bin/activate
# windows 激活虚拟环境
venv\Scripts\activate安装依赖库:
pip3 install -r requirements.txt安装 playwright浏览器驱动:
playwright install运行爬虫程序:
# 从配置文件中读取关键词搜索相关的帖子并爬去帖子信息与评论
python main.py --platform xhs --lt qrcode --type search
# 从配置文件中读取指定的帖子ID列表获取指定帖子的信息与评论信息
python main.py --platform xhs --lt qrcode --type detail
# 打开对应APP扫二维码登录
# 其他平台爬虫使用示例, 执行下面的命令查看
python main.py --help 数据保存:
- 支持保存到关系型数据库(Mysql、PgSQL等)
- 支持保存到csv中(data/目录下)
- 支持保存到json中(data/目录下)
视频教程: B站。
三、预览
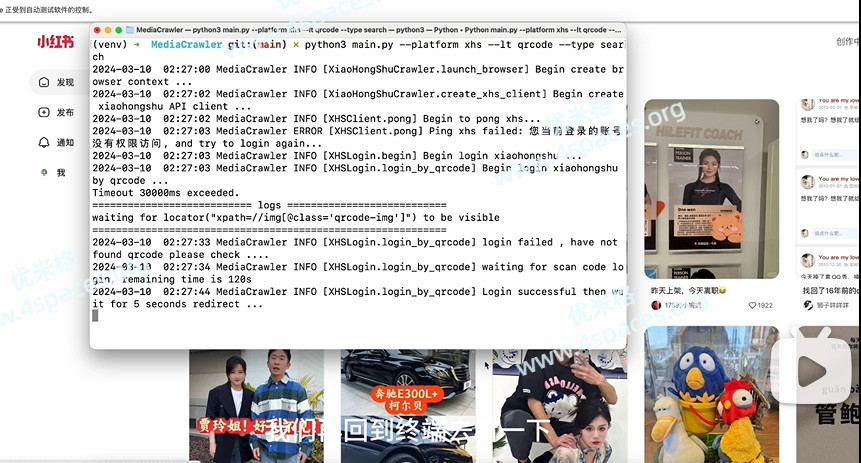
四、地址
项目: https://github.com/NanmiCoder/MediaCrawler

最新评论
没有磁力吗
不行,这个版本4K还是限速~
搞笑了,官网打不开的机场,检验倒数到0直接卡死了
都是ip6的,有ip4的吗?老电视不支持ip6