


方法定义:
1.reduceByKey(func[,num Tasks])
当键值相同的键值对(K,V)数据集调用此方法,他们的键对应的值会根据指定的函数(func)进行聚合,而键值(V,V)也进行合并,返回键值(V),最终返回一个键值对(K,V)数据集。当然,你也可以通过可选参数num Tasks,指定任务执行的次数。
2.groupByKey([num Tasks])
当键值对(K,V)数据集调用此方法,会返回一个键值对(K, Iterable
方法使用:
让我们用两种不同的方式来实现对单词出现次数进行统计,一种是reduceByKey,另一种是groupByKey。
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _).collect()
val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum)).collect()
尽管两个函数都能得到正确的结果,但是reduceByKey更适合作用在较大的数据集上,因为在对数据进行转换时,Spark知道在每个分区上可以对这些键值进行合并输出。
区别比较:
让我们通过下图来了解reduceByKey是如何操作的。注意相同机器上具有相同键值的键值对在进行数据转换前是如何合并的(通过将lamdba函数传递给reduceByKey)。然后lamdba函数会被多次作用于每个分区上的所有值,从而产生一个最后的结果。
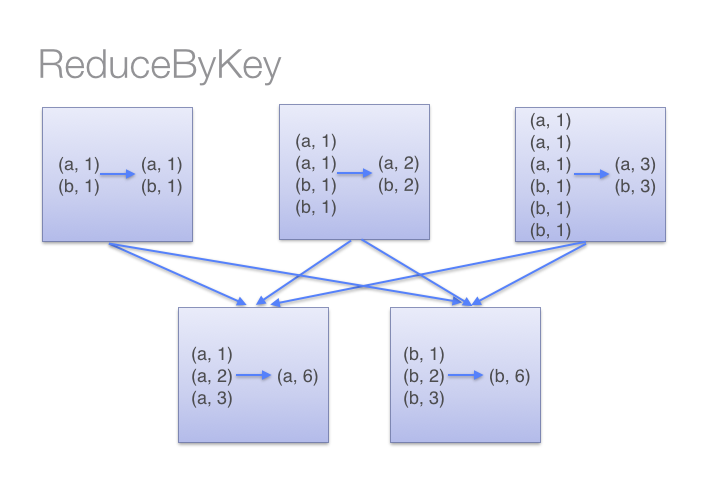
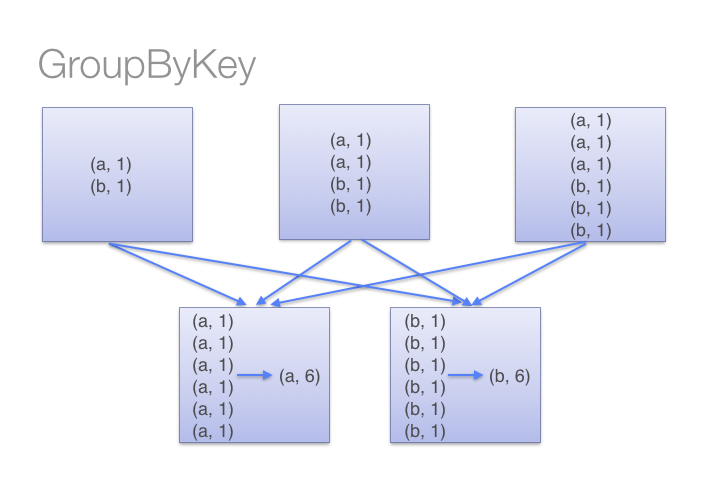
另一方面,当我们调用groupByKey时,所有的键值对都会被移动。通过网络传输这些数据完全没有必要。
为了确定将键值对移动到那台机器,Spark对键值对的键调用一个分区算法。当移动的数据量大于单台执行机器内存总量时 Spark 会把数据保存到磁盘上。 不过在保存时每次会处理一个 key 的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。以下函数应该优先于 groupByKey :
- combineByKey – 当你想要的返回值类型和你要组合的数据的输入的值的类型不同时可以使用此方法;
- foldByKey – 使用级联函数和中性“零值”来合并每个键的值。
参考文章:

最新评论
已经死了这个app
大哥 求求
一个人用就够,多人钱包伤不起啊
没有央视频道,这怎么玩?